Мы решили перевести знаменитый доклад Яндекса о работе с поведенческими факторами «Through-the-Looking Glass: Utilizing Rich Post-Search Trail Statistics for Web Search» (оригинал доступен по ссылке). Думаю, многие SEO-специалисты сделают выводы о важности и нюансах работы с поведенческими факторами.
Любопытно, что данный доклад был прочитан и опубликован только для американской аудитории на конференции CIKM 2013, проходившей с 27 октября по 1 ноября 2013 года в Бёрлингейме (США).
Сквозь стекло: использование обширных данных и поисковом пути после запроса в веб-поиске.
Алексей Толстиков, Михаил Шахрай, Глеб Гусев, Павел Сердюков
Yandex
Россия 199021 Москва, ул. Льва Толстого, 16
АННОТАЦИЯ
В то время как все чаще используются панели инструментов браузеров, возрастает важность обращения к данным о поведении пользователя, хранящимся в журналах событий. Анализ информации о поисковых путях показан с целью предоставления важных сведений об опыте пользователя, что помогает совершенствовать существующие поисковые системы. Однако практическое применение различных характеристик поискового пути для улучшения существующих рейтинговых моделей до сих пор не до конца исследовано. Используя реальные данные, мы провели масштабное исследование и оценку большого набора характерных особенностей поискового пути и пришли к выводу, что более глубокое изучение опыта пользователя, далеко выходящее за рамки его перехода на страницу результатов поиска, может улучшить существующие рейтинговые модели.
Категории и описание предмета изучения: H.3.3 [Хранение и поиск информации]: Информационный поиск
Ключевые слова: характеристики поведения пользователя; поисковые пути; время нахождения на странице
1. ВСТУПЛЕНИЕ
В последние годы данные о поведении пользователя играют все более важную роль при выполнении различных задач комплексного исследования. Наиболее известный способ получения данных о предпочтениях и выборе пользователей — анализ журналов посещений веб-страниц. Несмотря на то, что они предоставляют обширные данные о предполагаемом поведении пользователя, их надежность и ценность явно ограничены, поскольку огромная часть действий пользователя выходит за пределы перехода на страницу результатов поиска.
Все более частое использование панелей инструментов браузеров позволяет частично компенсировать нехватку данных о поведении пользователя после перехода на веб-страницу за счет просмотра журналов посещений, в которых содержится информация о действиях пользователя в сети. Уже было показано [1], что базовые данные о взаимодействиях пользователя с ресурсами веб-страницы, такие как время нахождения на странице, могут служить высокими показателями в рейтинговой модели сведений. Однако полная последовательность страниц с одинаковыми запросами, которые пользователь посетил после перехода на страницу с результатами поиска, так называемый «поисковый путь после запроса», еще недостаточно изучен как источник характеристик, способный улучшить ранжирование сведений, содержащихся в поисковых путях. Мы предполагаем, что подробный анализ поисковых путей может помочь в дальнейшем усовершенствовании существующих поисковых моделей по сравнению с уже известными характеристиками, такими как время нахождения на странице.
В настоящей работе мы проводим масштабное исследование различных характеристик поисковых путей, продолжая предыдущие исследования данных о поведении пользователя и их практической ценности для поиска в сети. Вслед за [7] мы представляем поисковые пути как древовидные структуры, где корнем являются результаты поисковых запросов, а ветвями — ряд переходов по гиперссылке. Являясь деревом, поисковый путь обладает его параметрами: количеством узлов, глубиной, шириной, средней длиной ветви. Кроме этих параметров поискового пути, мы также изучили и оценили некоторые новые, включая количество шагов поискового пути с имеющимся периодом отсутствия активности, наблюдаемого после их совершения. Некоторые из этих параметров поисковых путей уже подвергались исследованию в теоретических работах, таких как [7], но, насколько нам известно, их практическая польза для поиска в сети еще не была оценена по количественным показателям комплексного исследования. Подвергаясь комплексной оценке на уровне документа или домена страницы результатов поиска, большинство параметров значительно улучшают качество базовой модели поиска, которая использует существующие параметры поискового пути после запроса. Такой результат подтверждает наши вышеупомянутые предположения о том, что, выходя далеко за рамки времени нахождения пользователя на странице в своем исследовании, мы можем узнать больше о значимости результатов поисковых запросов.
Таким образом, важность данной работы определяется следующим: (1) мы провели масштабное исследование обширной группы параметров поисковых путей и их практической пользы в веб-поиске, (2) мы обнаружили, что подробное изучение параметров поискового пути может предоставить дополнительные сведения, необходимые для выполнения заданий по информационному поиску.
2. ПРОДЕЛАННАЯ РАБОТА
С точки зрения поисковой системы, данные о поведении пользователя удобнее всего встроить в существующую рейтинговую систему посредством развития новых параметров, отражающих различные качества взаимодействия пользователя с ресурсами веб-страницы. Одной из первых работ по использованию параметров поведения пользователя, взятых из журналов событий, для улучшения качества сравнительного ранжирования является работа [1]. Среди других параметров поведения пользователя авторы работы проанализировали основные статистические данные взаимодействий пользователя с ресурсами веб-страниц, включая различные изменения во времени нахождения на странице. Менее значимые данные об опыте пользователя в сети могут быть получены при анализе прокрутки и перемещений курсора мыши [4]. В данной работе мы также рассматриваем данные об опыте пользователя «выходящие за рамки его нахождения на странице», и мы также обращаемся в нашем исследовании к данным, выходящим за пределы первой страницы поискового пути. Еще один возможный подход к использованию данных о поведении пользователя — развитие способов поиска и обработки текстовой информации, основанного на языковых моделях исходных запросов, которые приводят к рассмотренному документу посредством поисковых путей, обнаруженных в журналах посещений [2]. Совокупная ценность поисковых путей была показана, чтобы превысить ценность стартовой страницы и страницы с результатами поиска, проводя их сравнения по разным показателям, таким как значимость, полнота освещения темы, тематическое разнообразие, новизна и практическая польза [8]. В нашем исследовании мы представляем поисковые пути в виде древовидных структур, как предложено в [7]. Мы также заимствуем часть основных параметров дерева, рассмотренных в данном исследовании. Некоторые из этих параметров подтвердили свою практическую полезность при нахождении лучшего поискового пути [5]. Бинарный характер результата запроса, указывающий на существование поискового пути после запроса, был использован для тренировки классификатора, обнаруживающего пустые клики [3].
3. ДАННЫЕ
Все опыты, описанные в настоящей работе, были проведены с использованием данных о поведении пользователя, содержащихся в анонимном журнале событий на панели инструментов браузера популярной поисковой системы, которой пользуются миллионы людей в разных странах. Каждая запись в этом журнале содержит (анонимный) идентификатор панели инструментов пользователя, временную отметку, а также детали действий в сети, такие как запрос, сделанный пользователем, URL посещенной страницы или закрытие окна браузера. Мы выбрали все записи, содержащиеся в журнале событий за трехмесячный период времени с 11 декабря 2012 года по 10 марта 2013 года. Эти данные содержат 3,0 бита запросов пользователя, 5,3 бита поисковых путей и 16 битов посещений страницы с 2,7 битами различных документов.
Из полученных данных мы выбрали поисковые пути, начинающиеся с запроса пользователя и состоящие из последовательных посещений веб-страницы одним и тем же пользователем и скорее всего относящиеся к одним и тем же информационным потребностям. Чтобы уменьшить помехи со страниц, не имеющих отношения к информационным потребностям пользователя, выраженным в исходном запросе, мы ограничивали поисковый путь в следующих случаях: (1) пользователь сделал новый запрос, (2) пользователь осуществил переход на стартовую страницу, ввел URL в адресную строку браузера или перешел на веб-страницу, используя закладку браузера, (3) отсутствие активности в течении более чем 30 минут (время ожидания в режиме простоя), (4) пользователь закрыл окно браузера. Это список правил, похожий на тот, который определяет поисковый путь согласно [7], за исключением правила «проверять email или вход в службу», которое представляется нелогичным, так как, фактически пользователь все еще может продолжать поиск, нажимая на гиперссылку, которая осуществляет переход пользователя на сайт, где требуется его отождествление.
4. ПАРАМЕТРЫ ПОИСКОВОГО ПУТИ
В данном разделе мы кратко описываем способ построения поисковых путей, похожий на тот, который предложен в [7]. Как было уже выше упомянуто, мы рассматриваем каждый поисковый путь как древовидную структуру. Узлы таких деревьев представляют собой уникальные страницы, а ориентированные ребра — переходы по гиперссылкам между ними. Таким образом, переходы пользователя по гиперссылке отображаются в виде передвижений по ветви дерева. Кроме того, если пользователь повторно посещает страницу, уже посещенную им во время одного из предыдущих шагов поискового пути, данный переход предстает, как перемещение пользователя назад к соответствующему узлу дерева, который он уже посетил. После этого новые страницы, посещенные посредством дальнейшего перехода по гиперссылке, если таковые есть, составляют новую ветвь дерева. Если пользователь возвращается на страницу с результатами поискового запроса и нажимает на новый документ, мы создаем новое дерево. На рис. 1 изображен пример образованной в результате таких переходов древовидной структуры. В следующем подразделе мы описываем параметры, которые могут характеризовать поисковый путь и которые мы используем как параметры для ранжирования в дальнейшем в этой работе.
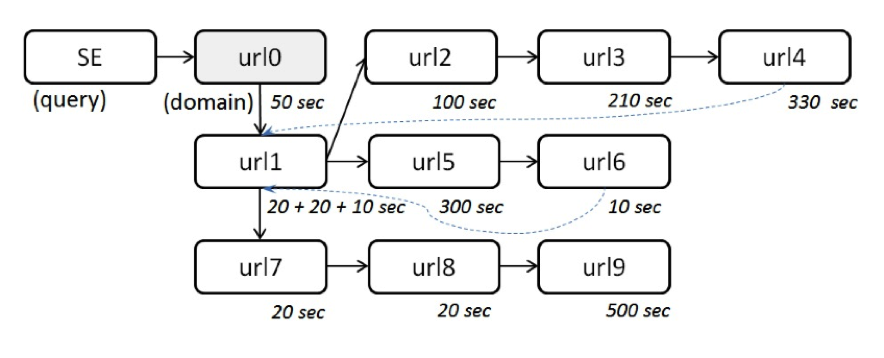 Рисунок 1: Поисковый путь, представленный в виде дерева.
Рисунок 1: Поисковый путь, представленный в виде дерева.
Узлы = 10, глубина = 4, ширина 3, длина ветви = 3, шаги = 12, повторные посещения страницы = 2, время = 1590, выполненные шаги = 6, длинные шаги = 3.
4.1 ПАРАМЕТРЫ ДЕРЕВА
• Количество узлов. Общее количество узлов дерева соответствует числу уникальных страниц, которые пользователь посетил в поисковом пути после запроса. Большие показатели данного параметра могут указывать на то, что первая страница поискового пути, выданная поисковой системой среди других результатов, не удовлетворила в полной мере информационных потребностей пользователя и заставила его переходить дальше по ссылкам. С другой стороны, большие показатели этого параметра более характерны для поисковых путей, образованных информационными запросами, чья информационная потребность не может быть удовлетворена единственной веб-страницей.
- Глубина — это расстояние между корнем дерева и самым отдаленным узлом, при этом под расстоянием между узлами дерева подразумевается количество ребер на кратчайшем пути, соединяющем эти два узла ребрами дерева. Глубокие деревья предположительно более характерны для поисковых путей, представляющих поиск на веб-сайте, страницы которого предстают в виде рядов, последовательно сформированных переходом по гиперссылкам в обоих направлениях. Речь может идти об информации, которая создана, чтобы ее просматривали, пролистывая упорядоченный список веб-страниц.
- Ширина поискового дерева — это количество его листьев. Листья представляют собой страницы с результатами запроса, за которыми не следовал переход вперед по гиперссылке. Ширина поискового пути совпадает с количеством ветвей, последнее качество было рассмотрено в [7]. Большие показатели этого параметра могут указывать на то, что основные информационные потребности многоаспектны, поиск, осуществляемый пользователем, похож на исследовательский по своей манере или домен с поисковыми страницами неудобно создан.
- Средняя длина ветви. Мы разбили поисковый путь на сегменты, каждый следующий сегмент начинается с повторного посещения уже просмотренной до этого страницы и формирует цепь последовательных переходов вперед по гиперссылке. Для каждой цепи мы определили ее длину, которая составляет количество ребер, образующих ветвь из которой составляется цепь. Мы не принимаем во внимание цепи длиной в 1, так как они не образуют новые ветви дерева. Средняя длина ветви получается из усреднения длин всех цепей, что соответствует разным ветвям дерева. Стоит упомянуть, что данная величина также равна ((узел-1)/ширина)+1.
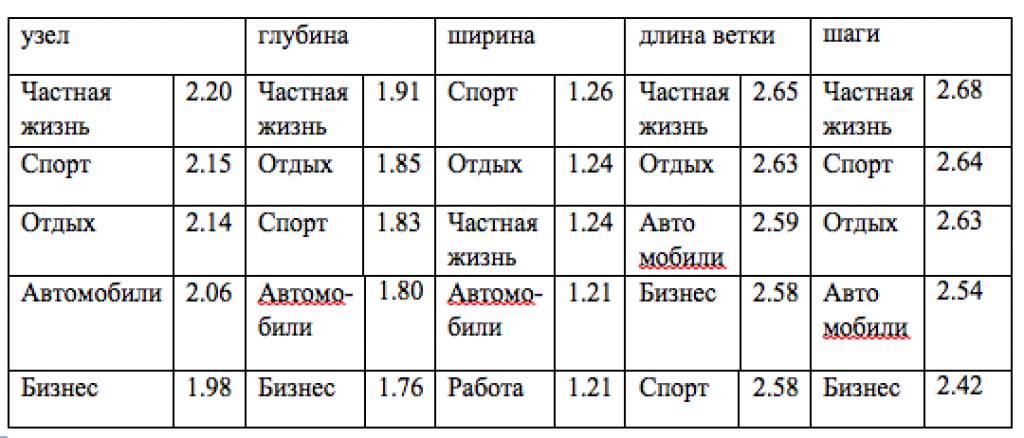
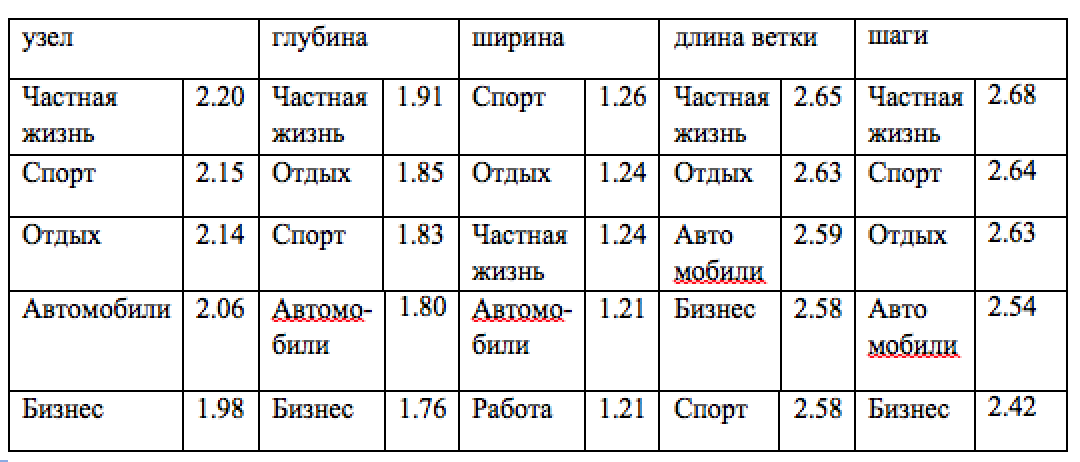
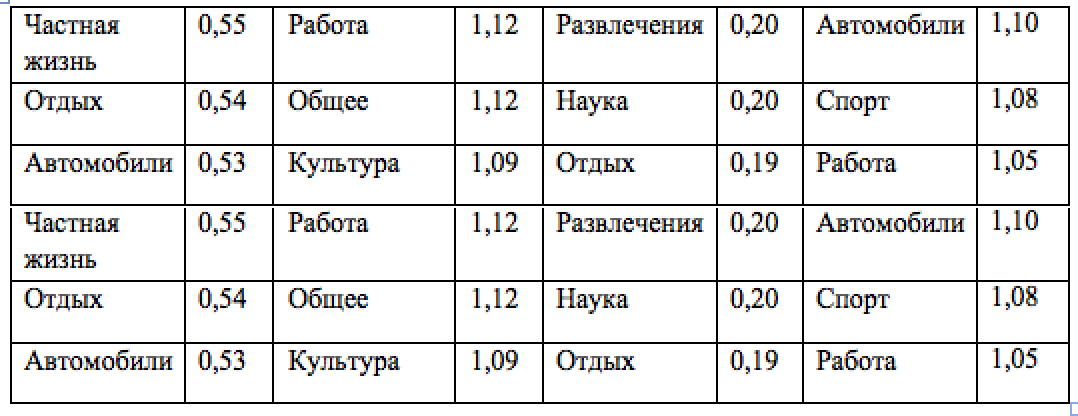
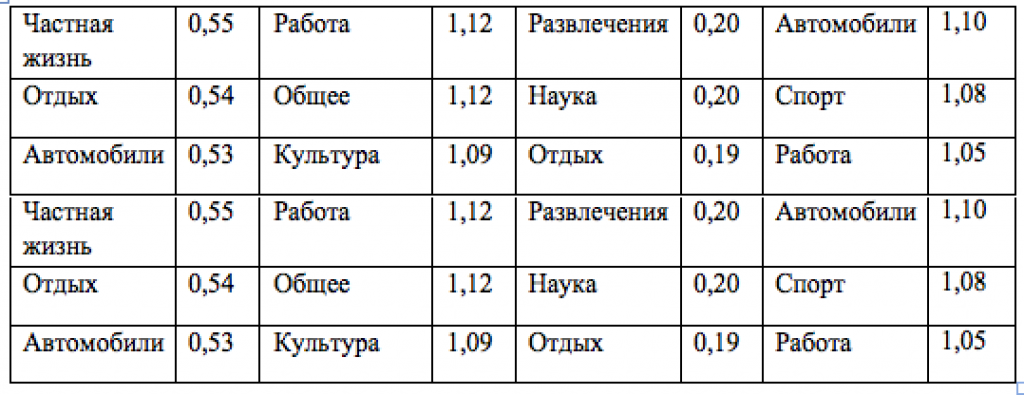 Таблица 1: Темы с наибольшим средним значением каждого из параметров, связанного с поисковым путем и объединенных доменами.
Таблица 1: Темы с наибольшим средним значением каждого из параметров, связанного с поисковым путем и объединенных доменами.
4.2. Параметры переходов.
Наравне с вышеупомянутыми параметрами, которые представляют характеристики самого поискового дерева и поэтому зависят только от его топологии, существуют и некоторые другие параметры поискового пути, отражающие различные качества перемещения пользователя по поисковому дереву.
- Количество шагов поискового пути — совокупное число переходов, совершенных пользователем во время перемещения по поисковому пути. Этот параметр похож на количество узлов, о чем уже говорилось выше, но отличается от него тем, что при подсчете количества шагов мы также учитываем все повторно просмотренные страницы.
- Количество повторных посещений — это число повторных посещений страницы, совершенных пользователем во время перемещения по поисковому пути. Количество повторных посещений может быть представлено как мера сложности пути. На самом деле, большие показатели количества повторных посещений показывает, что пользователь часто возвращался к ранее посещенным страницам, чтобы либо перейти с них на новые страницы, либо с получения информации, которую он не смог получить во время первого посещения данных страниц.
- Многообразие — количество различных доменов второго уровня, представленных страницами поискового пути.
- Количество выполненных шагов и количество длинных шагов — число шагов поискового пути, за которыми следует 30 или 300 секунд отсутствия активности соответственно. Таким образом, мы определяем выполненные шаги поискового пути таким же образом, как обычно определяют выполненные клики (см., напр., [6]). Выполненные шаги соответствуют страницам, которые, как показывает практика, заслуживают большого внимания со стороны пользователя.
Рис. 1 отражает пример поискового пути и показывает значения всех его параметров, описанных выше.
4.3.Объединение параметров
После того, как были выделены параметры для каждого индивидуального поискового пути, мы объединили их для всех поисковых путей посредством одного из двух возможных способов: на уровне первого документа поискового пути (объединение на уровне URL) и на уровне домена этого документа (объединение на уровне домена). В результате каждого типа объединения мы получили образцы поисковых путей, связанных либо с документом, либо с доменом. Для каждого вышеописанного параметра поискового пути мы посчитали среднее значение (av), стандартное отклонение(std), 10-й и 90-й процентиль (10th, 90th), максимальные и минимальные значения (min, max) и использовали их в качестве параметров в нашей рейтинговой модели. В следующем разделе мы проводим исследование того, как описанные параметры зависят от темы домена веб-страницы.
5. Параметры и темы домена
В этом разделе мы изучаем распределение параметров поискового пути, обусловленных различными темами их стартовых веб-страниц. С этой целью мы используем домены из собственной базы данных, распределенные вручную по темам. Мы использовали наивный байесовский классификатор, подготовленный на основе этих данных с использованием уникальных параметров страниц домена. Этот классификатор определяет каждый домен второго уровня, чьи документы представлены в нашем наборе данных поисковых путей с некоторыми темами, выбранными среди тем упорядоченной базы данных. Для каждого параметра среднего типа, объединенного на уровне домена (см. Раздел 4.3), мы посчитали его среднее значение на всех страницах в пределах одной и той же темы. Таким образом, каждой теме мы приписали средние значения каждого из рассмотренных параметров. В зависимости от рассматриваемого параметра мы распределяем все темы в рейтинге в соответствии с этим средним значением и представляет полученные результаты в Таблице 1. Как мы можем видеть, некоторые темы по естественным причинам попадают в соответствующий рейтинг, когда оцениваются по параметрам поискового пути. Например, пользователь, который находится на веб-сайте, посвященном продаже автомобилей, не может заранее знать какую точно машину он ищет. Пользователь также будет просматривать различные страницы, посвященные разным видам условий для отдыха, прежде чем поймет, какие есть возможные варианты. Похожие наблюдения относятся и к таким параметрам как глубина, ширина и шаги. Наибольшее количество выполненных шагов получено в таких темах, как Общество, СМИ и Наука, содержание которых в основном состоит из статей, предназначенных для глубокого прочтения. Кроме результатов, представленных в Таблице 1, мы также обнаружили некоторые явно выраженные закономерности в нижних строках рейтингов. К темам с наименьшими значениями выполненных шагов относятся Личная жизнь и Автомобили, у которых прослеживается довольно большое количество шагов. Несмотря на большое количество посещений, пользователь не склонен на долгое время задерживаться на страницах доменов этих тем. Эти результаты свидетельствуют о том, что параметры поискового пути могут быть использованы поисковой системой. В следующем разделе мы описываем расчеты параметров поискового пути и их практическую пользу для поиска в сети.
6. Расчеты
Рассчитывая параметры поискового пути, мы брали за основу большую базу данных пользовательских запросов, случайным образом выбранных из веб-поиска крупной поисковой системы. Для каждого запроса были предоставлены лучшие документы ведущими мировыми поисковыми системами с комментариями квалифицированных экспертов и отметками от «превосходно», «отлично», «хорошо», «удовлетворительно» до «плохо». В целом этот набор данных содержит 50 КБ запросов и 1.5 МБ оцененных пар запросов-документов. Во всех расчетах в качестве модели ранжирования мы использовали деревья решений Фридмана с возрастающим градиентом. Мы сравнили характеристики предлагаемых параметров с характеристиками следующего базового набора параметров (Basic): разновидность BM25 score, PageRank, коэффициенты CTR, объединенные на уровне домена и документа, и 7 изменений во времени нахождения на странице, разобранных в [1, Таблица 4.1]: TimeOnPage — TimeOnDomain and AverageDwellTime — DomainDeviation. Поэтому данная база достаточно мощная, легко поддается интерпретации и включает обширный ряд известных на настоящий момент параметров, основанных на времени нахождении на странице.
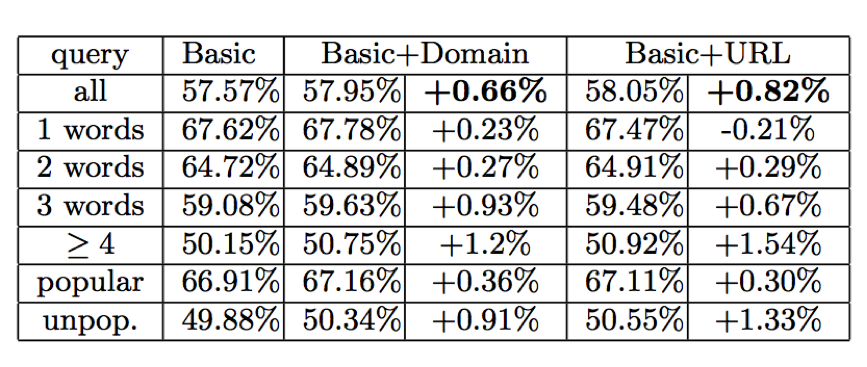 Таблица 2: Метрики NDCG@10, полученные при базовой модели, с использованием параметров, объединенных URL и доменом. Запросы, образующие 45.18% набора данных и с недельным рейтингом ≥ 10, названы распространенными. Разница в шрифте важна для статистики на 0.99% уровня доверительной вероятности.
Таблица 2: Метрики NDCG@10, полученные при базовой модели, с использованием параметров, объединенных URL и доменом. Запросы, образующие 45.18% набора данных и с недельным рейтингом ≥ 10, названы распространенными. Разница в шрифте важна для статистики на 0.99% уровня доверительной вероятности.
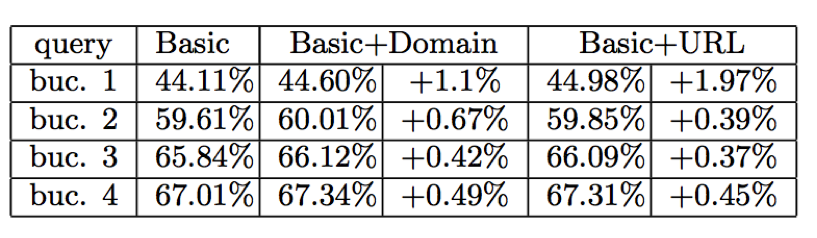 Таблица 3: Метрики NDCG@10, полученные на четырех различных уровнях доступности данных, от бакета 1 (наименее доступный) до бакета 4 (наиболее доступный).
Таблица 3: Метрики NDCG@10, полученные на четырех различных уровнях доступности данных, от бакета 1 (наименее доступный) до бакета 4 (наиболее доступный).
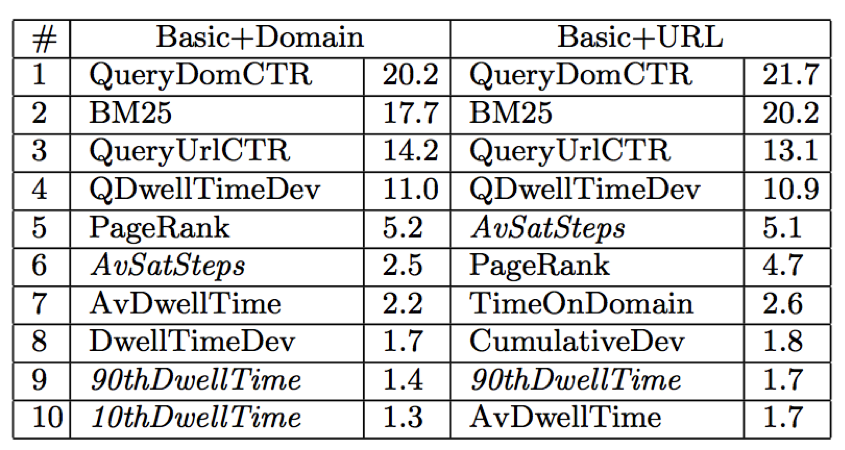 Таблица 4: 10 главных параметров по степени их важности.
Таблица 4: 10 главных параметров по степени их важности.
Мы разделили все запросы набора данных на две равные части, первая для моделей обучения и вторая для расчетов. В Таблице 2 мы показываем характеристики трех моделей, образованных с использованием: (1) основного набора параметров; (2) основные и объединенные с доменом параметры поискового пути и (3) основные и объединенные с URL параметры поискового пути. Параметры поискового пути, объединенные с доменом, и параметры поискового пути, объединенные с URL, показывают свою эффективность на системе тестов. Модель, образованная на основных параметрах без 7 изменений во времени нахождения на странице выполняется на уровне NDCG@5 = 55.9%. В связи с этим параметры поискового пути, основанные на URL, прибавляют 0.82% в качественном показателе в добавление к 2.9%, полученным за счет времени нахождения на странице. Мы также по отдельности оценили функционирование этих трех моделей с различными классами запросов. Мы обнаружили, что параметры поискового пути играют еще большую роль в длинных или редких запросах. Мы объясняем это следующим образом: объединяясь документами и доменами, наши параметры поискового пути распространяют важные свидетельства опыта пользователя на более сложные случаи, когда параметров базового поведения пользователя мало и поэтому они неинформативны. Чтобы подтвердить эту догадку, мы разбиваем все запросы теста на четыре почти равных части, представляющих другой уровень доступности данных поискового пути, измеряемых в количестве поисковых путей, состоящих, по крайней мере, из 2 шагов, которые были созданы рассматриваемым запросом. Полученные результаты, представленные в Таблице 3, показывают, что параметры поискового пути даже больше для запросов с недостаточными поисковыми путями. В Таблице 4, мы показываем 10 главных параметров согласно их полезности, которая измеряется весомым улучшением функции потерь на протяжении всего использования параметра в течение процесса обучения. Параметры поискового пути выделены курсивом.
7. ЗАКЛЮЧЕНИЕ
Мы провели масштабное исследование поисковых путей после запроса и их полезности для веб-поиска. Мы рассмотрели большой набор параметров поискового пути как потенциальный источник информации об опыте пользователя, который выходит за рамки клика по первой странице с результатами запроса. Детальные расчеты показывают значительный вклад параметров поисковых путей в мощную базовую поисковую модель. Насколько нам известно, большинство поисковых путей до этого не были измерены величинами комплексного исследования. Мы полагаем, что последующий подробный анализ поисковых путей, включая исследование их новых качеств и различных способов их объединения, может помочь еще больше улучшить существующие модели поиска по сравнению с уже известными параметрами поведения пользователя.
8. Сноски
[1] E. Agichtein, E. Brill, and S. Dumais. Improving web
search ranking by incorporating user behavior
information. In SIGIR, pages 19{26, 2006.
[2] M. Bilenko and R. W. White. Mining the search trails of surfing crowds: identifying relevant websites from
user activity. In WWW, pages 51{60, 2008.
[3] Q. Guo and E. Agichtein. Smoothing clickthrough data for web search ranking. In
SIGIR, pages 355{362, 2009.
[4] Q. Guo and E. Agichtein. Beyond dwell time: estimating document relevance from cursor movements and other post-click searcher behavior. In WWW, pages
569{578, 2012.
[5] A. Singla, R. White, and J. Huang. Studying
trailnding algorithms for enhanced web search. In SIGIR, pages 443{450, 2010.
[6] K. Wang, T. Walker, and Z. Zheng. Pskip: estimating relevance ranking quality from web search clickthrough data. In KDD, pages 1355{1364, 2009.
[7] R. W. White and S. M. Drucker. Investigating
behavioral variability in web search. In
WWW, pages 21{30, 2007.
[8] R. W. White and J. Huang. Assessing the scenic route: measuring the value of search trails in web logs. In SIGIR, pages 587{594, 2010.